
How to evaluate the product impact of the iPhone 16
At the Apple Developer Conference held earlier, the iPhone 16 series will be equipped with iOS 18 has been revealed. At the event, Apple showed off a series of convenient interactive experiences brought by Apple Intelligence, including a more powerful Siri voice assistant, Mail app that can generate complex responses, and Safari that aggregates web information. These upgrades will no doubt make the iPhone 16 line even more attractive. In order to use Apple Intelligence, a new feature of iOS 18, the iPhone 16 and 16 Pro series are equipped with A18 chips. An external blogger found in Apple's back end that the iPhone 16 series will use the same A-series chip, and the back end code mentions A new model unrelated to the existing iPhone. It includes four iPhone 16 series models, and the four identifiers all start with the same number, indicating that Apple is attributing them to the same platform. The new iPhone will have a stainless steel battery case, which will make it easier to remove the battery to meet EU market standards, while also allowing Apple to increase the density of the battery cell in line with safety regulations.

Wto: Members have more trade promotion measures than restrictions
The latest trade monitor released recently by the World Trade Organization shows that between mid-October 2023 and mid-May 2024, WTO members continued to introduce more trade promotion measures than trade restrictive measures. The WTO said it was an important signal of members' commitment to keep trade flowing amid the current geopolitical uncertainty. According to WTO statistics, during the monitoring period, WTO members adopted 169 trade promotion measures on commodities, more than the 99 trade restrictive measures introduced. Most of the measures are aimed at imports. Commenting on the findings, WTO Director-General Ngozi Okonjo-Iweala said that despite the challenging geopolitical environment, this latest trade monitoring report highlights the resilience of world trade. Even against the backdrop of rising protectionist pressures and signs of economic fragmentation, governments around the world are taking meaningful steps to liberalize and boost trade. This demonstrates the benefits of trade on people's purchasing power, business competitiveness and price stability. The WTO monitoring also identified significant new developments in economic support measures. Subsidies as part of industrial policy are increasing rapidly, especially in areas related to climate change and national security.

The largest password leak in history exposes nearly 10 billion credentials
The largest collection of stolen passwords ever has been leaked to a notorious crime marketplace, according to cybersecurity researchers at Cybernews. This leak, dubbed RockYou2024 by its original poster “ObamaCare,” holds a file containing nearly 10 billion unique plaintext passwords. Allegedly gathered from a series of data breaches and hacks accumulated over several years, the passwords were posted on July 4th and hailed as the most extensive collection of stolen and leaked credentials ever seen on the forum. “In its essence, the RockYou2024 leak is a compilation of real-world passwords used by individuals all over the world,” the researchers told Cybernews. “Revealing that many passwords for threat actors substantially heightens the risk of credential stuffing attacks.” Credential stuffing attacks are among the most common methods criminals, ransomware affiliates, and state-sponsored hackers use to access services and systems. Threat actors could exploit the RockYou2024 password collection to conduct brute-force attacks against any unprotected system and “gain unauthorized access to various online accounts used by individuals whose passwords are included in the dataset,” the research team said. This could affect online services, cameras and hardware This could affect various targets, from online services to internet-facing cameras and industrial hardware. “Moreover, combined with other leaked databases on hacker forums and marketplaces, which, for example, contain user email addresses and other credentials, RockYou2024 can contribute to a cascade of data breaches, financial frauds, and identity thefts,” the team concluded. However, despite the seriousness of the data leak, it is important to note that RockYou2024 is primarily a compilation of previous password leaks, estimated to contain entries from a total of 4,000 massive databases of stolen credentials, covering at least two decades. This new file notably includes an earlier credentials database known as RockYou2021, which featured 8.4 billion passwords. RockYou2024 added approximately 1.5 billion passwords to the collection, spanning from 2021 through 2024, which, though a massive figure, is only a fraction of the reported 9,948,575,739 passwords in the leak. Thus, users who have changed their passwords since 2021 may not have to panic about a potential breach of their information. That said, the research team at Cybernews stressed the importance of maintaining data security. In response to the leak, they recommend immediately changing the passwords for any accounts associated with the leaked credentials, ensuring each password is strong and unique and not reused across different platforms. Additionally, they advised enabling multi-factor authentication (MFA), which requires an extra form of verification beyond the password, wherever possible, to strengthen cyber security. Lastly, tech users should utilize password manager software, which securely generates and stores complex passwords, mitigating the risk of password reuse across multiple accounts.
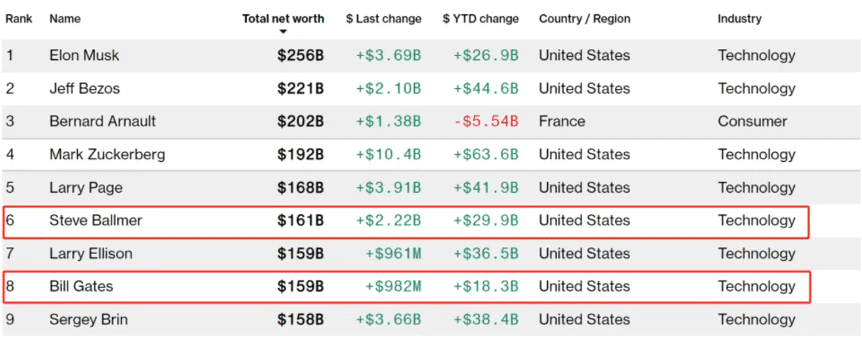
Former Microsoft CEO Ballmer wealth surpassed Gates, he only did one thing
On July 1, former Microsoft CEO and President Steve Ballmer surpassed Microsoft co-founder Bill Gates for the first time on the Bloomberg list of the world's richest people to become the sixth richest person in the world. According to the data, as of the same day, Ballmer's net worth reached $157.2 billion, while Gates's wealth was $156.7 billion, falling to seventh place. The latest figures, as of July 6, show that Ballmer's wealth has grown further to $161 billion, and Gates' wealth is $159 billion. This is the first time Ballmer's net worth has surpassed Gates', and it is also the rare time in history that an employee's net worth has surpassed that of a company founder. Unlike Musk, Jeff Bezos and others, Ballmer's wealth was not accumulated through entrepreneurial success as a business founder, but simply because he chose to hold Microsoft "indefinitely." As Fortune previously reported, Ballmer is the only individual with a net worth of more than $100 billion as an employee rather than a founder.

US' ban on high-tech investment cannot stifle China's high-tech development
US President Joe Biden signed an executive order on Wednesday restricting investments in China, intended to further stymie China's advances in three cutting-edge technology areas: semiconductors and microelectronics, quantum information technologies and certain artificial intelligence systems. The "decoupling" of high tech from China began under Donald Trump, and the Biden administration has continued that ambition. However, the new order doesn't target US investments already invested in China, but the new ones. The Biden administration has repeatedly claimed that the US restrictions will be narrowly targeted and will not "have a fundamental impact on affecting the investment climate for China." Biden's new executive order is still subject to consultation with the US business community and the public and is not expected to take effect until next year. The order has been brewed for a long time and has generated a lot of publicity. But almost no one believes that this executive order will deal a new practical blow to Chinese high technology, because almost everyone knows that China needs American technology more than American money. The order has gained much attention because it is seen as part of a broader trend of the US drifting away from China. The promulgation and brewing process of the executive order reflects the strong desire of American political elites to suppress China's high-tech development, as well as a fierce game between those supporting the executive order and the concerns of the technology and economic sectors about a potential backfire on the US. It is a kind of compromise. Washington obviously hopes that major allies will follow Biden's executive order. The UK's Sunak government has made cautious statements, stating that it is consulting business and the financial sector before deciding whether to follow suit. In fact, China also has the ability to influence the extent to which Biden's executive order is implemented, as well as the extent to which the US will go in terms of "decoupling" from China. We are definitely not just passive recipients of US policies. American political elites are eager to "decouple" from China as quickly and deeply as possible, but they fear two things: First, this will immediately damage the performance of relevant high-tech companies in the US, undermine their influence and further innovation. The current Biden administration, in particular, does not want to incur strong resentment from Silicon Valley and Wall Street toward the escalating "decoupling," which will ultimately lead to the loss of support for the Democratic Party. Second, they are afraid of pushing China toward more resolute independent innovation to achieve breakthroughs in key technologies such as chips. If the US "decoupling" policy gives birth to major technological achievements in China, it means that Washington will completely lose the gamble: They originally wants to stifle China's high-tech development, but ends up strangling their own companies. What China needs to do next is to fully unleash our innovation vitality, continuously reduce our dependence on high-tech products from the US, and prove that as long as we are determined to achieve independent innovation, we have the ability to accomplish things. We need to prove that being pressured by the US will only make us stronger. As long as there are several solid proofs of this trend, the US policy community will fall into unprecedented chaos, and their panic will be much more severe than when they saw the rapid expansion of the Chinese economy before Trump started the trade war. Regardless of the future of China-US relations, the current battle will be the key battle that determines the future competition between China and the US. China can only win and cannot afford to lose. High-tech products such as chips are not isolated. The innovation power of China's entire manufacturing industry and the creative vitality of the whole society are the foundation for shaping these key achievements. When pressured by the US, our society needs to generate confidence and resilience from all directions, and we need to accelerate and seize every opportunity, rather than shrink and simply defend. Otherwise, the US will gain the upper hand in momentum, and we will truly be in a passive and defensive position. We must see that the US is on the offensive, but its offensive is becoming weaker and weaker, and it is always hesitant with each step. What is presented to China are difficulties and risks, but also the dawn of victory.
